The Performance Tuning Magic Show @ DPS2022
- Guy Glantser

- Jul 10, 2022
- 5 min read
I'm excited about delivering a pre-con session in Data Platform Virtual Summit 2022.

First, what is Data Platform Virtual Summit 2022?
It's one of the biggest conferences in the world focused on the Microsoft Data Platform. This year in September, it's going to be the eighth edition, with lots of tracks and sessions in different areas and multiple time zones. The conference is online, and it's completely free, so if you haven't registered yet, do it now. I'll wait...
Second, what is a pre-con session?
It stands for pre-conference session. It's a full 8-hour training class, which is held a week before the conference itself. There are multiple pre-cons , each covers a specific topic in-depth. These training classes are not free, but they are invaluable. And if you register now, you can get a 50% discount, so it's really a very good value for money. You can see all pre-con sessions here: https://dataplatformgeeks.com/dps2022/training-classes/.
My pre-con session is about performance tuning in SQL Server and Azure SQL. But this is not a standard training class. It's a magic show!
I have been tuning queries for more than 20 years. Once in a while, I get to be a magician. It goes like this: a customer calls me and complains about some slow-running query. I look at the query, do some magic, and after a couple of minutes, the query is running fast like the flash. I love these moments.
So I decided to gather all the magic tricks that I have learned over the years, and I prepared an 8-hour educating and entertaining show. During the show, we will look at different queries and use cases, and we will apply all kinds of magic tricks to make them run really fast. But unlike traditional magic shows, we will learn how these magic tricks actually work.

To give you a taste of what you can expect from the show, I'll teach you one magic trick, right here, right now.
The Story
Let's say we have two tables: Operation.Members and Billing.Payments. The primary key in the "Operation.Members" table is on the "Id" column (INT), and there is a corresponding foreign key on the "MemberId" column (NVARCHAR(20)) in the "Billing.Payments" table.
As you can see, there is database design problem here - we use inconsistent data types for columns that represent the same values. I see problems like this once in a while. It can happen for various reasons, but usually none of them is a good reason. The best thing to do is, of course, to fix the design issue by changing the data type of one of the columns. In this case, we should change the data type of the "MemberId" column in the "Billing.Payments" table to INT.
But this is not that easy. It requires refactoring of many modules, parameter definitions, variable definitions, client applications, etc. Also, if the "Billing.Payments" table is very big, then this operation can result in a long downtime and a heavy use of server resources. I still recommend to do it, but if you can't, then you should at least write your queries properly to handle this situation.
Consider the following query:
SELECT
MemberId = Members.Id ,
MemberFirstName = Members.FirstName ,
MemberLastName = Members.LastName ,
PaymentAmount = Payments.Amount ,
PaymentDateTime = Payments.DateAndTime
FROM
Operation.Members AS Members
INNER JOIN
Billing.Payments AS Payments
ON
Members.Id = Payments.MemberId
WHERE
Members.RegistrationDateTime >= '2022-01-01'
AND
Members.RegistrationDateTime < '2022-01-02'
ORDER BY
MemberId ASC ,
PaymentDateTime ASC;
Here is the plan:
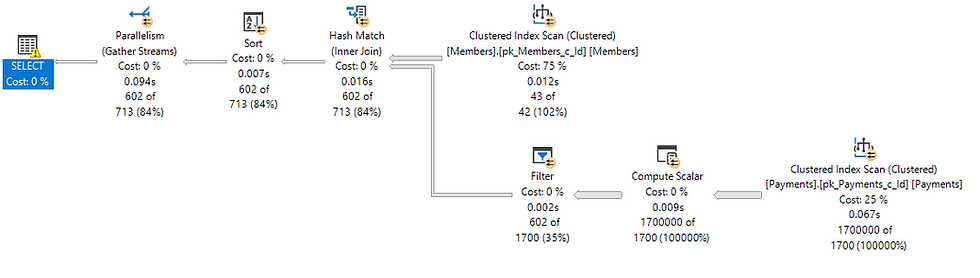
Base on statistics, the optimizer (almost) perfectly estimated that there are 42 members who registered on the first of January 2022. There is a non-clustered index on the MemberId column in the "Billing.Payments" table, so it would have made sense to use a nested-loops join (only 42 iterations) with an index seek using that index. But for some reason, the optimizer chose to use a hash-match join with a clustered index scan operation. This resulted in 8,905 logical reads from the "Billing.Payments" table.
Why is that?
If you look carefully at the execution plan above, you will see a warning on the left-most SELECT operator. It is always a good idea to pay attention to the optimizer warnings. Here is the warning:

This warning tells us that in order to perform the join condition, the optimizer had to add an expression that implicitly converts the data type of the "MemberId" column to INT. It warns us that this type conversion may affect cardinality estimate (the estimated number of rows). It also warns us that it might not be able to use an index seek operation because of that type conversion.
If we look at the Compute Scalar operator, we will see that this is exactly what it does. It calculates the expression: CONVERT_IMPLICIT (INT , [Billing].[Payments].[MemberId]).
We already know that the data types don't match. The problem is that the optimizer decided to convert the data type of the "MemberId" column from NVARCHAR(20) to INT instead of the other way around. It has to convert 1.7 million values (the number of rows in the "Billing.Payments" table), and it had to perform a hash-match join and a clustered index scan, because it can't seek on an expression. It can only seek on the index key itself (MemberId).
If the optimizer chose to convert the "Id" column in the "Operation.Members" table from INT to NVARCHAR(20), then it would only need to convert 43 values (from the "Operation.Members" table), and then it would be able to use a nested-loops join and an index seek operation. This would result in a much better plan.
So why did the optimizer make the wrong choice?
Well, the optimizer didn't really have a choice. There is a deterministic precedence order for data types in SQL Server. When the optimizer needs to compare expressions of different data types, it must always convert the data type with the lower precedence to the data type with the higher precedence. Unfortunately, NVARCHAR has lower precedence than INT.
You can see the entire precedence order here: https://docs.microsoft.com/en-us/sql/t-sql/data-types/data-type-precedence-transact-sql?view=sql-server-ver16.
The Magic Trick
The optimizer doesn't have a choice, but we do. Instead of letting the optimizer perform an implicit conversion, we can force an explicit conversion. But in this case, we will convert the INT to NVARCHAR(20).
Here is the revised query:
SELECT
MemberId = Members.Id ,
MemberFirstName = Members.FirstName ,
MemberLastName = Members.LastName ,
PaymentAmount = Payments.Amount ,
PaymentDateTime = Payments.DateAndTime
FROM
Operation.Members AS Members
INNER JOIN
Billing.Payments AS Payments
ON
CAST (Members.Id AS NVARCHAR(20)) = Payments.MemberId
WHERE
Members.RegistrationDateTime >= '2022-01-01'
AND
Members.RegistrationDateTime < '2022-01-02'
ORDER BY
MemberId ASC ,
PaymentDateTime ASC;
And here is the new execution plan:
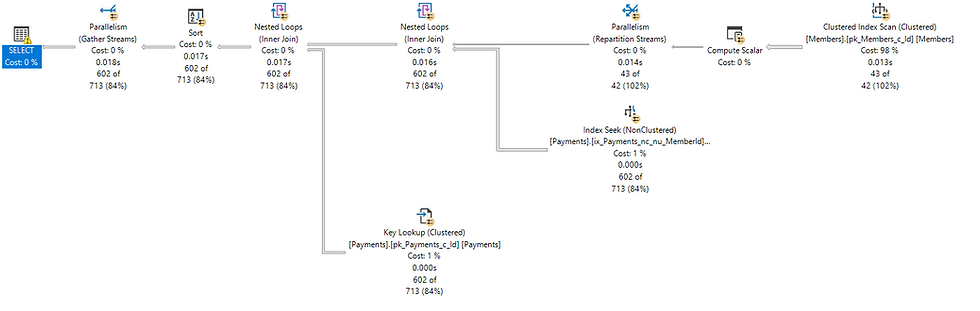
Look how the Compute Scalar operator moved to the upper path, now calculated only 43 times, as opposed to 1.7 million times. Also notice that we managed to get the desired nested-loops join along with the index seek operation. The number of logical reads from the "Billing.Payments" table dropped from 8,905 to 2,220.
There is still a warning, and it's the same as before, only this time it warns us about an explicit conversion rather than an implicit one. But this time we can safely ignore the warning, because we are responsible for the explicit conversion, and we put it there for a good reason.
Join the Show
If you want to learn a lot more magic tricks like this one, then register to my pre-con and join the show. You can register here: https://dataplatformgeeks.com/dps2022/product/the-performance-tuning-magic-show-by-guy-glantser/.
When you register, use discount code "GUY" to get 60% off.


