The Complete Guide to Temporary Tables and Table Variables - Part 2
- Guy Glantser

- Jan 4, 2022
- 3 min read
In part 1 I provided a basic comparison between temporary tables and table variables. If you haven't read it, then I recommend you read it before reading part 2 (this post).
In this blog post I am going to focus on a performance comparison between the two. As I explained in part 1, the biggest difference between the two, which is related to performance, is statistics. Temporary tables have statistics, very similar to regular tables, while table variables don't have statistics at all.
Statistics are the number-one tool that the cardinality estimator has in order to estimate the cardinality (number of rows) in various stages in the execution plan.
For example, let's assume that the Casino.Games table has one million rows, and we run the following query:
SELECT
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
FROM
Casino.Games
WHERE
Profit BETWEEN $10.00 AND $20.00;
There is an index on the Profit column, and the optimizer needs to estimate the number of rows in the table in which the profit is between $10.00 and $20.00. If there are few rows, then it will probably choose an index seek with a few key lookups. But if there are many rows, then it will prefer to perform a clustered index scan.
Here is the execution plan:
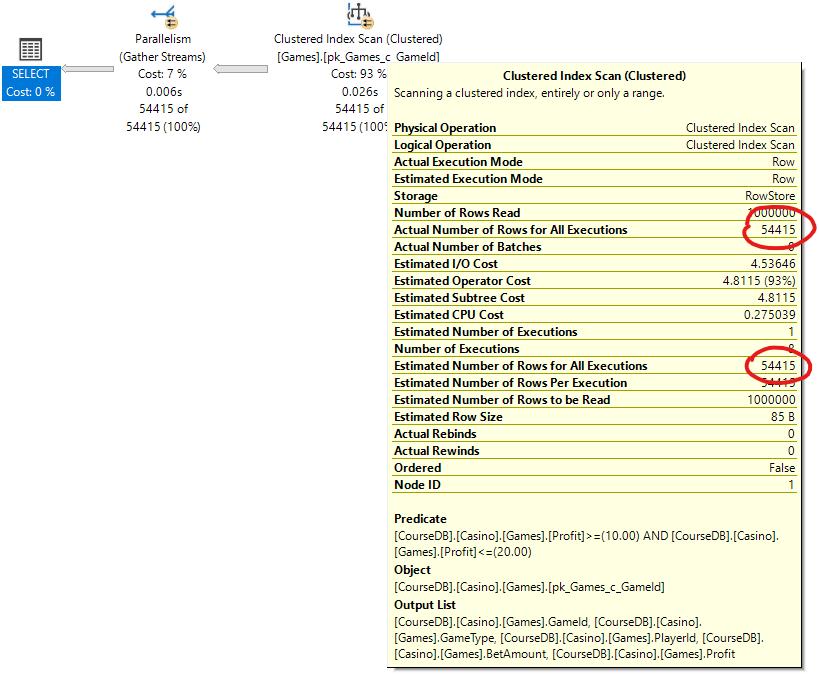
See how the cardinality estimator used the statistics on the Profit column to come up with a perfect estimate of the number of rows. Based on this estimation, the optimizer chose to use a clustered index scan, and avoid 54,415 key lookups.
Now, let's try to do the same thing with a temporary table. First, we will create the temporary table, then we will copy the data from the Casino.Games table to the temporary table, then we will create a non-clustered index on the Profit column, and finally, we will run the same query against the temporary table.
CREATE TABLE
(
GameId INT NOT NULL ,
GameType NVARCHAR(50) NOT NULL ,
PlayerId INT NOT NULL ,
BetAmount MONEY NOT NULL ,
Profit MONEY NOT NULL ,
CONSTRAINT
pk_Games_c_GameId
PRIMARY KEY CLUSTERED
(GameId ASC)
);
INSERT INTO
(
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
)
SELECT
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
FROM
Casino.Games;
CREATE NONCLUSTERED INDEX
ix_Games_nc_nu_Profit
ON
#Games (Profit ASC);
SELECT
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
FROM
WHERE
Profit BETWEEN $10.00 AND $20.00;
The execution plan looks the same:
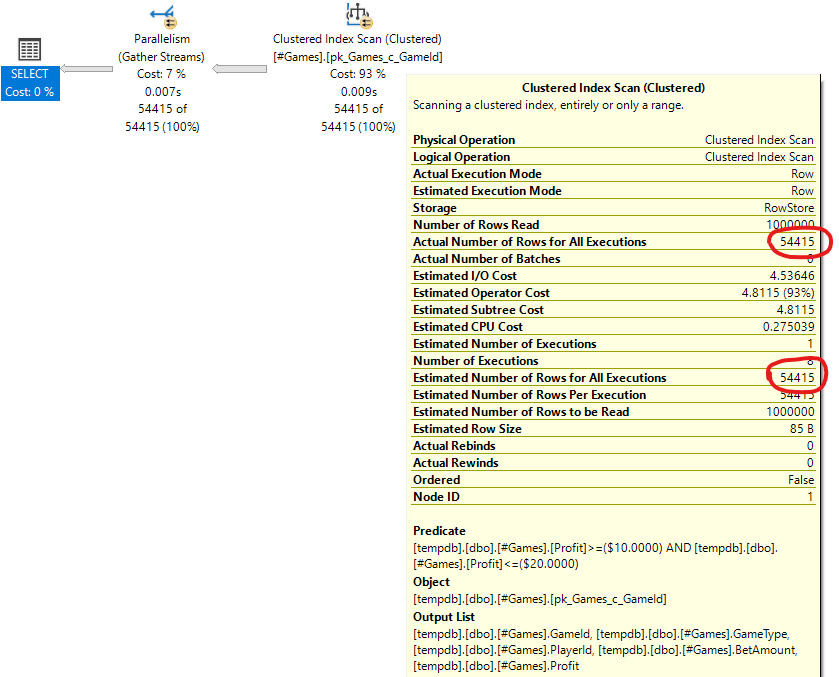
This is because the temporary table has statistics just like the regular table.
But what will happen if we try to do the same with a table variable?
DECLARE
@Games
TABLE
(
GameId INT NOT NULL PRIMARY KEY CLUSTERED ,
GameType NVARCHAR(50) NOT NULL ,
PlayerId INT NOT NULL ,
BetAmount MONEY NOT NULL ,
Profit MONEY NOT NULL INDEX ix_Games_Profit (Profit ASC)
);
INSERT INTO
@Games
(
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
)
SELECT
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
FROM
Casino.Games;
SELECT
GameId ,
GameType ,
PlayerId ,
BetAmount ,
Profit
FROM
@Games
WHERE
Profit BETWEEN $10.00 AND $20.00;
The result execution plan depends on the version of SQL Server that you are using. If you are using SQL Server 2019 or higher version, or if you are using Azure SQL, then you will see the following execution plan:
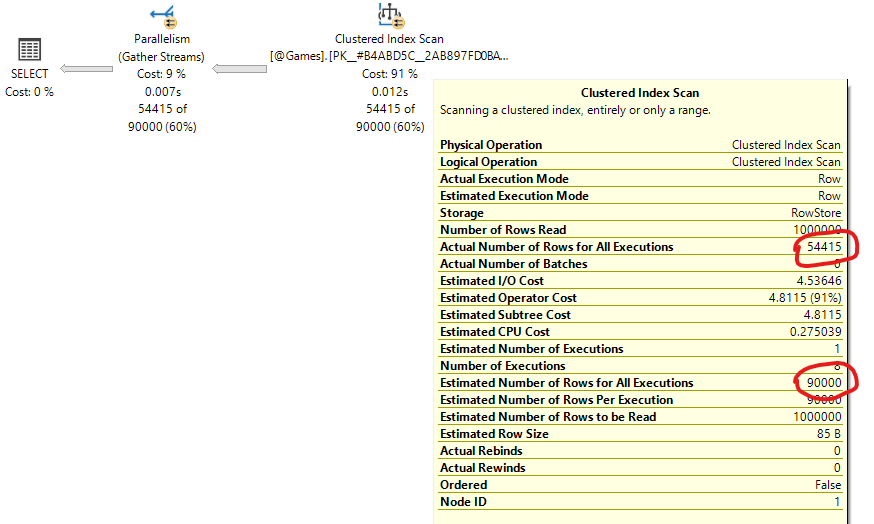
The optimizer estimates 90,000 rows, while the actual number of rows is 54,415, as we already know. This estimate (90,000) is the result of a feature called Deferred Compilation for Table Variables along with some optimization rules. I will explain these later.
If you are using SQL Server 2017 or earlier version, then you don't have Deferred Compilation for Table Variables, and your execution plan will probably look like this:
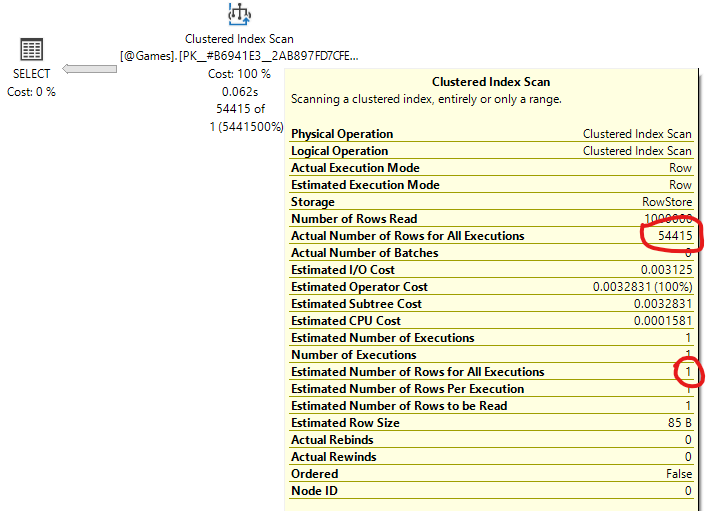
Notice that the optimizer estimated only one row. In the case of table variables, it will always estimate one row, because there are no statistics.
We can already see one implication of this wrong estimate. If you look back at the different execution plans, then you will see two other interesting properties: "Number of Rows Read" and "Estimated Number of Rows to be Read". These numbers represent the total number of rows scanned, before applying the predicate (Profit BETWEEN $10.00 AND $20.00). In our case, they simply represent the number of rows in the table. When we used a temporary table, the optimizer estimated the number of rows to be read correctly (1,000,000), and it produced a parallel plan to scan the clustered index more efficiently. On the other hand, when we used a table variable (the last execution plan), the optimizer estimated only one row to be read, and therefore produced a serial plan. But then a single thread had to scan the entire one-million-row table.
This is just a small example of the implications that statistics (or in the case of table variables - lack of statistics) can have on query performance. There are many more, and I will cover them in part 3...


