סדר העמודות באינדקס
- Geri Reshef

- 15 hours ago
- 5 min read
כבר הרבה מאוד שנים שה-execution plans כוללים המלצות לאינדקסים, וכך גם כלים כמו sys.dm_db_missing_index_details, ובימינו התווספו להם כלי AI שאמורים להחליף אותנו או את שיקול דעתנו. הבעייה העיקרית עם כל הנ"ל שהם נותנים המלצות טובות למקרה ספציפי, אבל לנו יש עדיין את שיקול הדעת כיצד להימנע מריבוי אינדקסים, וכיצד לבנות אותם כך שיביאו תועלת גם במקרים אחרים; ובמקרה השני עוסק הפוסט הזה. נכין קודם כל את רשימת החומרים:
Use tempdb
Go
Drop Table If Exists Bad;
Select 1 N,
*
Into Bad
From sys.messages
Where 1=2
Drop Table If Exists Good;
Select 1 N,
*
Into Good
From sys.messages
Where 1=2
Declare @N Int=1;
While @N<=100
Begin
Insert
Into Bad
Select @N,
*
From sys.messages;
Insert
Into Good
Select @N,
*
From sys.messages;
Set @N+=1;
End;
ALTER TABLE dbo.Bad
ADD CONSTRAINT PK_Bad
PRIMARY KEY CLUSTERED (N, message_id, language_id)
WITH (DATA_COMPRESSION = PAGE);
ALTER TABLE dbo.Good
ADD CONSTRAINT PK_Good
PRIMARY KEY CLUSTERED (N, message_id, language_id)
WITH (DATA_COMPRESSION = PAGE);
Create Index Idx_is_event_logged_severity_language_id
On Bad(is_event_logged,severity,language_id)
With (Data_Compression=Page);
Create Index Idx_severity_is_event_logged_language_id
On Good(severity,is_event_logged,language_id)
With (Data_Compression=Page);
Drop Table If Exists Languages;
Select Cast(lcid As SmallInt) language_id,
*
Into Languages
From sys.syslanguages;
Alter Table Languages Alter Column language_id SmallInt Not Null;
ALTER TABLE dbo.Languages
ADD CONSTRAINT PK_Languages
PRIMARY KEY CLUSTERED (language_id);מה במצרכים:
טבלת Bad שתייצג את האינדקס הלא נכון כפי שנראה בהמשך, ושיש בה כ-33 מיליון שורות, על ידי שכפול של טבלת sys.messages מאה פעם: קודם עמודה is_event_logged שהיא עמודה שמקבלת 0 או 1 (מאוד לא סלקטיבית), אחריה עמודה severity שמקבלת 16 ערכים שונים (יותר סלקטיבית), ולבסוף עמודה language_id. האינדקס הזה נועד לתמוך בשליפה הכוללת join עם עוד טבלה ופילטר על טבלה זו; חוץ מהמפתח הראשי שאינו קשור לכך.
טבלת Good הזהה כמעט לגמרי לטבלה הנ"ל, וההבדל הוא רק באינדקס, בו העמודה הראשונה היא severity היותר סלקטיבית, ואחריה is_event_logged הפחות.
טבלת Languages המתבססת על sys.languages לצורך join עם הטבלאות הנ"ל על עמודה language_id. המפתח הראשי הוא עמודה language_id שמתבססת על lcid של טבלת המקור, אבל שונתה מ-int ל-small int כדי להתאים לסוג הנתון שבעמודות שב-Bad & Good.
נתחיל ממה שאינו שונה, ונריץ את השאילתות הבאות:
Set Statistics IO On;
Drop Table If Exists #B;
Select N,message_id,language_id,severity,is_event_logged
Into #B
From Bad
Where is_event_logged=0
And severity=16
And message_id=106;
Drop Table If Exists #G;
Select N,message_id,language_id,severity,is_event_logged
Into #G
From Good
Where is_event_logged=0
And severity=16
And message_id=106;
Set Statistics IO Off;Table 'Bad'. Scan count 8, logical reads 30556, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(2200 rows affected)
(1 row affected)
Table 'Good'. Scan count 8, logical reads 30556, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(2200 rows affected)
(1 row affected)
הפלטים מופנים לטבלאות זמניות כדי לחסוך את זמן העברת הנתונים מהשרת לעמדה ואת הריפרוש של המסך. הביצועים זהים למרות שהאינדקסים שונים. למשל: אם האינדקס הלא סלקטיבי מפלטר 50% מהנתונים ומתוכם הסלקטיבי מפלטר 1% (כך שנישארים עם חצי אחוז), והאינדקס הלא סלקטיבי מפלטר 1% מהנתונים ומתוכם הלא סלקטיבי מפלטר 50% (כך שנשארים שוב עם חצי אחוז) - המערכת תסרוק ותשלוף בשני המקרים רק חצי אחוז מהנתונים. אין הבדל.
מה בכל זאת ההבדל או מתי כן יהיה הבדל? נניח שאנחנו רוצים לשלוף רק לפי העמודה הלא סלקטיבית: האינדקס הראשון יאפשר לנו להגיע ל-50% הנתונים הרלוונטיים, בעוד שהשני לא מכיוון שהעמודה הסלקטיבית היא שנייה ונצטרך לעבור על 100% מהנתונים (כפול!) שזה לא נחמד, אבל בשני המקרים מדובר בשליפות מאוד ארוכות ולא נחמדות. לעומת זאת אם נרצה לשלוף רק לפי העמודה הסלקטיבית, באינדקס הראשון נצטרך לעבור על 100% מהנתונים (כי העמודה הסלקטיבית היא השנייה), אך באינדקס השני - נצטרך לעבור על 1% בלבד מהנתונים! כלומר - כששולפים על פי שתי העמודות , אין הבדל; אבל כששולפים על פי עמודה אחת מהשתיים המאונדקסות הרווח הרבה יותר גדול כשהסלקטיבית ראשונה. מכאן שכל עוד לא נאמר אחרת וכל עוד אין שיקולים נוספים, עדיף שהעמודה הראשונה תהיה הכי סלקטיבית.
אילו שיקולים נוספים יש לקחת בחשבון? למשל:
אם בשום מקרה אחר לא מפלטרים לפי העמודה הסלקטיבית, אבל בהרבה מקרים נוספים מפלטרים לפי העמודה הלא סלקטיבית - כנראה שאין טעם שהסלקטיבית תהיה ראשונה.
אם נניח יש לנו אינדקס עם העמודות A,B,C כאשר A סלקטיבית ו-B לא, וכעת יש ליצור אינדקס על עמודות A,B,D; יתכן שכדאי במקרה השני שהסדר יהיה B,A,D או אולי D,B,A כי כבר יש אינדקס שתומך ב-A לבדו וכדאי שיהיה גם אינדקס שיתמוך גם ב-B או ב-D כשהם לבדם.
אלא שיש דבר נוסף שמחזק את המסקנה הנ"ל, הביטו בשליפות הבאות:
Set Statistics IO On;
Drop Table If Exists #B;
Select N,message_id,L.language_id,severity,is_event_logged
Into #B
From Bad T
Inner Join Languages L
On T.language_id=L.language_id
Where is_event_logged=0
And severity=12;
Drop Table If Exists #G;
Select N,message_id,L.language_id,severity,is_event_logged
Into #G
From Good T
Inner Join Languages L
On T.language_id=L.language_id
Where is_event_logged=0
And severity=12;
Set Statistics IO Off;
מה-execution plan ניתן להתרשם שהשליפה מ-Bad פי 4 יותר טובה מהשליפה מ-Good, האמנם? חשדנו מתעורר כשאנחנו רואים שה-nested loops במקרה הזה מתחיל מטבלה Bad ולא מ-Languages. מה ההבדל? ב-nested loops המערכת מחפשת לכל שורה בטבלה העליונה את כל ההתאמות בתחתונה. אם בטבלה אחת יש 5 שורות ולהן 100 שורות מתאימות בטבלה השנייה, עדיף להתחיל מהטבלה "הרזה" ולגשת ל"שמנה" 5 פעמים - פעם לכל שורה, מאשר להתחיל מהגדולה ולגשת לקטנה 100 פעם (אנחנו מניחים ששתי הטבלאות מאונדקסות למשעי ולכן כל חיפוש כשלעצמו לא עולה הרבה אבל הרבה חיפושים מצטברים למחיר גבוה). מדוע במקרה הראשון המערכת מעדיפה לצאת מטבלה Bad שלאחר הפילטור יש בה 2200 שורות (בדקתי...) ולא מטבלה Languages שיש בה 34 שורות בלבד?
נסתכל אם כך ב-properties של האופרטור של טבלה Bad הנ"ל:
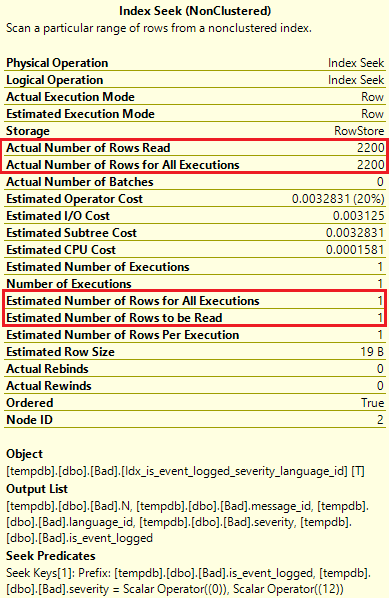
שורו הביטו וראו: המערכת העריכה שיש ב-Bad רק שורה אחת כשבפועל היו 2200 (לאחר פילטור). האם לא הרצנו update statistics? לא קשור ולא יעזור. אולי משהו עם parameter sniffing? גם לא - אין כאן פרמטרים ב-Where אלא ערכים מפורשים ולא יעזור אם נוסיף Option Recompile. אם כך מה קרה? בגלל שעמודה is_event_logged היא כל כך לא סלקטיבית (כמעט כל הערכים הם 0) - היא פוגעת אנושות ביכולת של המערכת להיעזר בסטטיסטיקות, והתוצאה היא תחזית שגוייה ותוכנית עקומה.
מה קורה בשליפה השנייה?

כאן כבר הסיפור שונה לגמרי: הסטטיסטיקות מדוייקות לחלוטין ונבחרה תוכנית יעילה ומתאימה לנתונים. נסתכל בסטטיסטיקה של ה-IO:
Table 'Languages'. Scan count 0, logical reads 4400, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Bad'. Scan count 1, logical reads 6, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(2200 rows affected)
(1 row affected)
Table 'Good'. Scan count 1, logical reads 7, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Languages'. Scan count 1, logical reads 4, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(2200 rows affected)
(1 row affected)
התוכנית השגוייה גרמה ל-IO גדול ומיותר בטבלה Languages בגלל ההערכה המוטעית שב-Bad יש רק שורה אחת לאחר הפילטור.
לסיכום: ככלל יש להעדיף אינדקסים בהם העמודות הולכות מהיותר סלקטיבית לפחות סלקטיבית, למרות שלכאורה אין הבדל אם יש פילטר הנעזר בכולן; גם כי האינדקס שימושי כשמשתמשים רק בעמודה הראשונה (או בעמודות הראשונות שלו) ולכן תרומתו תהיה גדולה יותר עם עמודות סלקטיביות בהתחלה, וגם כי עמודה לא סלקטיבית בראש - פוגעת ביכולת להשתמש בסטטיסטיקה.


